
From Linux Primitives to Kubernetes Security Contexts
August 2025
In Kubernetes, containers typically start with root privileges.
This happens because, by default, container processes run as UID 0 unless overridden.
Kubernetes does not impose a non-root policy; it inherits whatever the image defines.
This isn't a bug, it's a design choice carried over from Docker.
While convenient during development, it introduces unnecessary risk in production environments.
If an attacker compromises the container, root access increases the likelihood of privilege escalation to the host.
The Kubernetes API offers several ways to restrict container privileges using the Security Context.
With it, you can control the user a container runs as, manage Linux capabilities, enforce read-only filesystems, and block privilege escalation.
However, despite its importance, Security Contexts are often misunderstood or misapplied.
Many teams discover these controls only after a security audit or scanner flags a running container.
The next steps are usually reactively patching the config, suppressing the warning and moving on.
Before we get into Kubernetes SecurityContexts, we need to understand what they're actually configuring under the hood.
Table of Contents
- Table of Contents
- Linux Primitives Beneath Kubernetes
- Syscalls: The Kernel's API Surface
- Control Groups (cgroups): Enforcing Resource Limits
- Namespaces: Isolating What a Process Can See
- From Kernel Primitives to Developer Abstractions
- Linux User IDs and Permissions
- User Namespaces and UID Mapping in Containers
- How Docker Manages UIDs
runAsUserandrunAsNonRoot- Linux Capabilities
allowPrivilegeEscalation- Privileged Containers
- readOnlyRootFilesystem
- Seccomp Profiles
- AppArmor
- fsGroup and supplementalGroups
- How fsGroup Works with CSI Volumes
- Live Debugging: Diagnosing SecurityContext Failures
- Troubleshooting: When Security Context Conflicts with Container Behavior
- Summary and Best Practices
Linux Primitives Beneath Kubernetes
A container in Kubernetes is just a regular Linux process.
It runs directly on the host's kernel, but it's isolated using namespaces (for things like networking, mounts, and process IDs) and cgroups (for resource limits).
It also gets its own virtual filesystem, which is an isolated root directory.
There's no virtual machine here.
It's just Linux, sandboxed.
That's why it really matters who the process runs as inside the container; especially if it's root.
The securityContext field in a pod spec is a declarative way to configure how that process interacts with the kernel.
But Kubernetes doesn't enforce these settings itself.
It passes them down to the container runtime, which translates them into kernel-level instructions at container start.
Every setting you apply in a pod spec ultimately maps to low-level kernel features like syscalls, namespaces, cgroups, or capabilities.
To configure these effectively, you need to understand what each one does.
So before touching YAML, let's dissect the kernel-level primitives that SecurityContexts rely on.
Syscalls: The Kernel's API Surface
In Linux, user-space applications can't interact with hardware or kernel-managed resources directly.
Every interaction must go through the kernel, and the only sanctioned way to do that is via system calls.
System calls are predefined entry points that expose core kernel functionality.
 1/3
1/3The kernel works as a middle-man between your app and the hardware. When your Java application accesses a file on the filesystem, it initiates a syscall to the Linux kernel.
 2/3
2/3The Kernel knows how to access the underlying storage and lets your app retrieve the files. You could think of syscalls as API calls.
 3/3
3/3Similarly, if your Node.js app has to initiate a network connection, it still has to go through the kernel with a system call.
You can think of system calls as the kernel's API—over 300 entry points grouped by what they do.
Some handle files, some manage processes, others deal with networking or memory.
Each one has a unique ID in the kernel and takes specific arguments to tell the kernel exactly what to do.

Take the open syscall—it needs a file path, an access mode like read or write, and permission bits.
You can see the exact options and signature by checking the manual:
bash
man 2 open | grep -A 8 "SYNOPSIS"
SYNOPSIS
#include <fcntl.h>
int open(const char *pathname, int flags, ...
/* mode_t mode */ );
int creat(const char *pathname, mode_t mode);
int openat(int dirfd, const char *pathname, int flags, ...Here's how it looks when a real application makes these calls:
bash
strace -e trace=openat ls /tmp 2>&1 | head -5bash
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
openat(AT_FDCWD, "/tmp", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 3Or socket, which asks for a network domain like IPv4, a type like TCP, and the protocol you want to use.
You can inspect the socket and connect syscall signatures:
bash
man 2 socket | grep -A 8 "SYNOPSIS"
SYNOPSIS
#include <sys/socket.h>
int socket(int domain, int type, int protocol);Here's how these work together in a real network request:
bash
strace -e trace=socket,connect curl -s http://httpbin.org/ip 2>&1 | grep -E "(socket|connect)"bash
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 5
connect(5, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("192.168.2.1")}, 16) = 0The socket() call creates a TCP socket (AF_INET + SOCK_STREAM), then connect() establishes the connection to the remote server.
Even high-level code, like a simple network request in Node.js, still ends up triggering a socket syscall behind the scenes.
This level of access gives user-space applications immense power.
But it also exposes a large attack surface, especially when privileged capabilities are involved.
For instance, the CAP_NET_ADMIN capability capability unlocks dozens of networking syscalls ranging from setting interface flags to modifying routing tables.
Each of those calls takes arguments that can be used in wildly different ways, depending on the context.
So two processes with the same capability can behave very differently, depending on which syscalls they invoke and how they use them.
This is where the problem starts: the kernel trusts that you know what you're doing.
That's why Linux adds another layer to contain that risk: control groups, or cgroups.
Control Groups (cgroups): Enforcing Resource Limits
Control groups are kernel-level mechanisms that restrict how much CPU, memory, I/O, and other resources a process—or a group of processes—can consume.
They define how much of the system each one is allowed to use.
Say you're running a JVM application.
You can assign it to a cgroup that caps its memory at 256MB and restricts it to a single CPU core.
Now take a second process—maybe a Node.js app. You can place it in a separate cgroup with its own constraints.
Each cgroup defines a resource boundary.
You control how much each process gets, and the kernel enforces it.
 1/4
1/4In this case, I have a control group for the JVM.
 2/4
2/4I can create a control group that limits access to CPU, memory, network bandwidth, etc.
 3/4
3/4Each process can have its control group. I could create a second control group for the Node.js app.
 4/4
4/4I can fine-tune the settings for the new control group and further restrict the available resources for that process.
This lets you isolate workloads by physical limits on what they can consume.
But while cgroups enforce resource boundaries, they don't isolate what a process can see or interact with.
For that, Linux relies on another primitive: namespaces.
Namespaces: Isolating What a Process Can See
While cgroups control how much a process can consume, namespaces control what a process can see.
They determine which part of the system a process believes it's running in.
For example, with network namespaces, a process only sees its own interfaces and traffic.
It can't see packets or sockets from outside its namespace.
Namespaces isolate identity and scope.
With a mount namespace, a process sees a private filesystem view.
It might believe it sees /etc, /var, and /home, but it's only accessing a container-specific overlay.
 1/4
1/4Since kernel version 5.6, there are eight kinds of namespaces and the mount namespace is one of them.
 2/4
2/4With the mount namespace, you can let the process believe it has access to all directories on the host, when in fact it does not.
 3/4
3/4The mount namespace is designed to isolate resources — in this case, the filesystem.
 4/4
4/4Each process can see the same filesystem, while still being isolated from the others.
As of Linux kernel 5.6, there are eight namespace types.
bash
uname -r
5.15.167.4-microsoft-standard-WSL2
lsns
NS TYPE NPROCS PID USER
4026531834 time 17 1035
4026531835 cgroup 17 1035
4026531837 user 17 1035
4026531840 net 17 1035
4026532242 ipc 17 1035
4026532253 mnt 17 1035
4026532254 uts 17 1035
4026532255 pid 17 1035Each isolates a distinct dimension of system identity.
That means you can run multiple processes on the same machine, each in its own isolated environment, each with resource limits, and each believing it's alone.
Together with cgroups, namespaces form the backbone of container isolation.
But configuring them manually is complex and error-prone.
Managing syscalls, cgroups, and namespaces directly is powerful—but not practical for day-to-day development.
What if you could abstract them into a simpler interface?
That's exactly what Docker did.
By combining Linux namespaces and cgroups with filesystem overlays and a clean CLI, Docker made it easy to define, package, and run isolated workloads.
From Kernel Primitives to Developer Abstractions
Docker is a popular way to manage containers in a developer-friendly way.
Docker is not the only way to run containers, though.
There are other tools that abstract control groups and namespaces, such as Podman (Red Hat) and CRI-O (Red Hat).
Instead of managing syscalls, cgroups, and namespaces manually, you define a container image, run a single command, and the runtime sets everything up behind the scenes.
At their core, these platforms are just orchestration layers on top of three key Linux kernel features: Syscalls, Control Groups and namespaces
When combined, these primitives give you secure, lightweight, isolated environments—containers.
At this point, we've seen how Linux isolates containers using namespaces and resource controls.
But isolation isn't just about what a process can see or consume.
It's also about who the process is, and what permissions it has.
Linux User IDs and Permissions
In Linux, every process runs with a User ID, or UID.
The UID is the kernel's primary access control mechanism.
It defines ownership and tells what the process can access or modify.
You can verify the configured boundaries on most systems by inspecting /etc/login.defs.
bash
grep UID_ /etc/login.defs
UID_MIN 1000
UID_MAX 60000
#SYS_UID_MIN 100
#SYS_UID_MAX 999By convention, UID 0 means root, which has full control over everything.
UIDs 1-999 are usually for system services running in the background.
UIDs 1000 and above are assigned to regular users and applications.
You can confirm this division by listing user accounts and their UIDs.
bash
awk -F: '$3 < 1000 { print $1, $3 }' /etc/passwd
root 0
daemon 1
bin 2
man 6
...
_apt 100
sshd 105And those assigned to regular users:
bash
awk -F: '$3 >= 1000 { print $1, $3 }' /etc/passwd
nobody 65534
docker 1000Each time a process attempts a privileged operation, the Linux kernel checks its UID to decide whether that action should be allowed.
In containerized environments, this creates a subtle risk.
Many containers still run as UID 0.
If that UID maps directly to the host, a compromised container could gain real root access on the node.
To prevent this, Linux introduces user namespaces.
User Namespaces and UID Mapping in Containers
The user namespace lets you remap UIDs inside a container to unprivileged UIDs on the host.
This means a process can run as UID 0 (root) inside the container, while the kernel maps it to an unprivileged UID like 2000 outside.
From the container's perspective, the process is root and can do anything.
But from the host's perspective, it's just a regular user with no elevated privileges.
 1/3
1/3On the host system, User 0 (root) has complete administrative privileges while regular users (1000-2000, 2000-4000) have limited permissions.
 2/3
2/3Container 1 creates a user namespace where host user 1000 is mapped to root (User 0) inside the container, providing administrative privileges within the isolated environment.
 3/3
3/3Multiple containers can run simultaneously with different user mappings - Container 1 maps host user 1000 to root, while Container 2 maps host user 2000 to root, maintaining isolation.
This UID mapping prevents container processes from gaining root access to the host, even if they appear to be root in their own environment.
How Docker Manages UIDs
Docker uses both namespaces and process UID settings to manage security inside containers.
By default, the process runs with the UID defined in the container image—usually UID 0.
Unless user namespaces are explicitly enabled, UID 0 inside the container is also UID 0 on the host.

That's a problem.
If the container is compromised, the attacker gains root-level privileges over any accessible host resources.
This is why running containers as a non-root user is a critical best practice.
Even if isolation breaks, the process still has limited permissions.
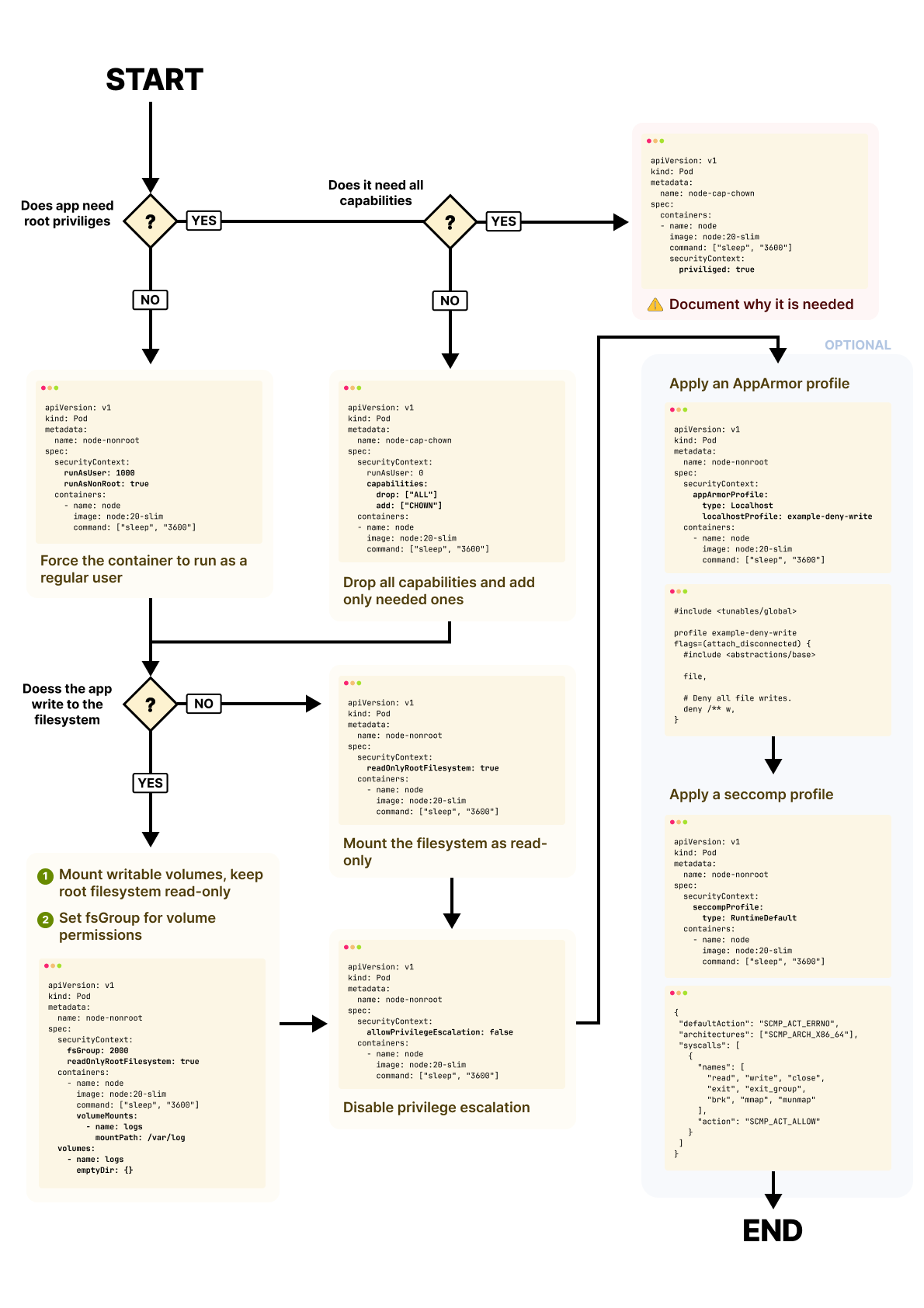
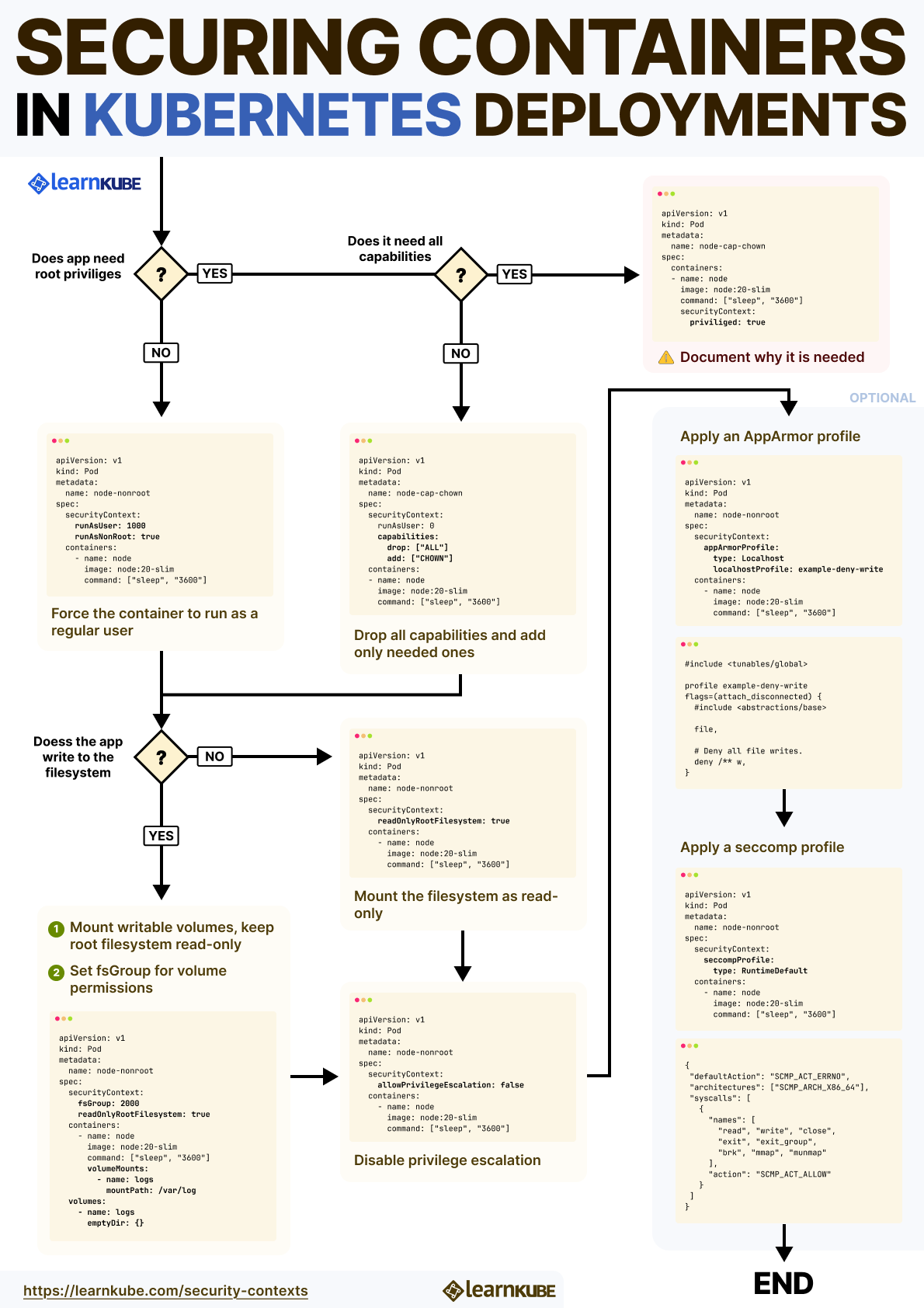
runAsUser and runAsNonRoot
Kubernetes builds on these kernel-level security controls using SecurityContext.
runAsUser and runAsNonRoot options in securityContext let you explicitly control the UID that a container process runs as.
runAsUser sets the exact UID for the process:
pod.yaml
spec:
securityContext:
runAsUser: 1000This means the container will start as UID 1000 instead of root.
This setting will apply to all containers in the Pod unless overridden.
But you're not required to use 1000 specifically.
You can choose any UID that exists in the image and has access to the required files.
Even if there's no matching entry in /etc/passwd, the kernel can still run the process as long as the UID is valid.
To make sure the container never runs as root—regardless of image defaults—Kubernetes offers the runAsNonRoot flag:
pod.yaml
spec:
securityContext:
runAsNonRoot: trueIf the container tries to start as UID 0, Kubernetes blocks it—even if runAsUser isn't explicitly set.
For stronger guarantees, you can combine both fields:
pod.yaml
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: trueThis setting ensures the process runs as a specific non-root UID, and any future changes to the image or spec won't accidentally elevate privileges.
Let's inspect a widely used official image that includes a non-root user by default:
bash
docker run --rm -it node:20-slim cat /etc/passwd
node:x:1000:1000::/home/node:/bin/bashThis shows that the node user is predefined with UID 1000.
However, this only defines the user.
To check which user the image actually runs as by default, inspect the runtime UID:
bash
docker run --rm node:20-slim id
uid=0(root) gid=0(root) groups=0(root)Despite defining a node user, the container runs as root by default.
To enforce non-root execution, you must either modify the Dockerfile to include:
bash
USER nodeOr override it in Kubernetes.
To achieve this let's create a minikube cluster.
bash
minikube startThen apply the following node-nonroot.yaml file:
node-nonroot.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-nonroot
spec:
securityContext:
runAsUser: 1000
containers:
- name: node
image: node:20-slim
command: ["sleep", "3600"]You can verify if runAsUser: 1000 is respected and overrides the image's root default:
bash
kubectl apply -f node-nonroot.yaml
pod/node-nonroot created
kubectl exec node-nonroot -- id
uid=1000(node) gid=1000(node) groups=1000(node)Running a container as a non-root user is a solid start, but some applications still need access to specific system-level operations to function properly.
That's where Linux capabilities come in.
Linux Capabilities
Capabilities define which privileged operations a process is allowed to perform.
Rather than granting full root access, the Linux kernel splits root privileges into fine-grained units like CHOWN, NET_ADMIN, and SYS_PTRACE.
Each capability grants just one class of operations.
In a traditional Linux system, the root user has full access to everything.
But under the hood, many of these powers are broken out into smaller units called capabilities.
They are like a menu of root powers.
 1/2
1/2User 0 (root) has all capabilities by default, including the full range of privileged operations from CHOWN to NET_BIND_SERVICE.
 2/2
2/2User 1000 has limited capabilities like NET_BIND_SERVICE but lacks most root privileges.
You can assign only the entries your process needs, and drop the rest.
Let's say your application needs to change file ownership using the chown system call.
Normally, only root can change file ownership using the chown syscall.
But instead of running the entire container as UID 0, you can selectively grant just the capability required to perform that action.
One of those fine-grained capabilities is CAP_CHOWN, which allows a process to change file ownership—even if it's not root.
Kubernetes exposes this through the securityContext.capabilities field.
You can run the container as a non-root UID and add just the CHOWN capability.
Kubernetes doesn't let you change security settings like securityContext.capabilities of a Pod after it's created.
node-cap-chown.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-cap-chown
spec:
containers:
- name: node
image: node:20-slim
command: ["sleep", "3600"]
securityContext:
runAsUser: 0
capabilities:
drop: ["ALL"]
add: ["CHOWN"]We explicitly drop all capabilities first to ensure a clean baseline, then add back only CHOWN.
Let's delete the existing Pod and recreate it with the updated spec:
bash
kubectl delete pod node-nonroot --force
pod "node-nonroot" force deleted
kubectl apply -f node-cap-chown.yaml
pod/node-cap-chown createdThe container still runs as a non-root user, but now it can perform a privileged operation.
Let's confirm the container is not root, but it can perform chown.
bash
kubectl exec node-cap-chown -- id
uid=0(root) gid=0(root) groups=0(root)
kubectl exec node-cap-chown -- sh -c "touch /tmp/test && ls -l /tmp/test"
-rw-r--r-- 1 root root 0 Jul 5 08:53 /tmp/test
kubectl exec node-cap-chown -- sh -c "chown 1234:1234 /tmp/test && ls -l /tmp/test"
-rw-r--r-- 1 1234 1234 0 Jul 5 08:53 /tmp/testThe container is running as UID 0 with only CHOWN allowed.
The next step is to verify that the container has only the CHOWN capability—and nothing more.
Let's run a few root-only operations from inside the container:
bash
kubectl exec node-cap-chown -- mount -t tmpfs tmpfs /mnt
mount: /mnt: permission denied.
kubectl exec node-cap-chown -- date -s "2024-01-01"
date: cannot set date: Operation not permittedBoth mount and date -s fail.
These syscalls mount() and settimeofday() needs capabilities like CAP_SYS_ADMIN or CAP_SYS_TIME, which we haven't granted.
Now let's confirm the capabilities at the kernel level:
bash
kubectl exec node-cap-chown -- cat /proc/1/status | grep CapEff
CapEff: 0000000000000001Decode it to human-readable form:
bash
printf "%x\n" 1 | xargs -I{} capsh --decode={}
0x0000000000000001=cap_chownThe container runs as a non-root user with only the CHOWN capability.
So, how does Kubernetes enforce this?
It doesn't.
Well, not directly.
You declare your intent in the securityContext, but enforcement happens deeper in the stack.
The kubelet passes the configuration to the container runtime and the runtime applies the requested capabilities when launching the container.
This is done via the Linux capset() system call.
From that point on, the Linux kernel handles enforcement.
 1/4
1/4The kubelet polls the control plane for pods. If it finds one, it downloads the spec.
 2/4
2/4The Kubelet delegates container operations to runtime interfaces (CRI, CNI, CSI).
 3/4
3/4The container runtime sets capabilities on the kernel for enforcement.
 4/4
4/4Linux kernel enforces capabilities for all containers through system calls.
But figuring out which capabilities your application actually needs isn't always straightforward.
Some tools document this clearly, but many don't—especially older or less-maintained ones.
A good starting point is to remove everything using drop: ["ALL"], then add capabilities back one by one until the container works.
This trial-and-error approach is common and works well for simple setups.
If you need more precision, you can trace system calls using tools like seccomp or audit logs.
This lets you see exactly which capabilities the process tries to use at runtime.
By running as a non-root user and enabling only the few capabilities your app truly needs, you reduce exposure without breaking functionality.
But there's a remaining risk: what if the process tries to gain more privileges after it starts, even if it begins as a non-root user?
allowPrivilegeEscalation
Some binaries are designed to do exactly that.
This is often done using mechanisms like setuid binaries, which are programs that automatically run with elevated privileges when executed.
That means a container can start as a non-root user but still end up with root-level privileges mid-execution.
Kubernetes addresses this with the allowPrivilegeEscalation setting.
Setting allowPrivilegeEscalation: false tells the container runtime not to allow the process to gain more privileges than it started with.
To do that, the container runtime sets the no_new_privs flag on the process at launch.
This flag is a kernel-enforced bit that locks privilege boundaries for the entire process tree.
You can verify that it's active by inspecting the container's main process.
bash
cat /proc/1/status | grep NoNewPrivs
NoNewPrivs: 1A value of 1 confirms that the process is explicitly prohibited from gaining any additional privileges—even if it executes a setuid binary.
This is a Linux kernel feature that tells the kernel to deny any privilege escalation, even if the binary tries.
It's simple, fast, and effective, especially in containers based on general-purpose Linux images, which often include tools like sudo or su.
Let's demonstrate what allowPrivilegeEscalation: true setting does with a practical example.
We'll create a container that runs as the nobody user and configure sudo to allow privilege escalation.
privilege-escalation.yaml
apiVersion: v1
kind: Pod
metadata:
name: privilege-escalation
spec:
restartPolicy: Never
containers:
- name: sudo-container
image: ubuntu:latest
command: ["/bin/bash", "-c"]
args:
- |
apt-get update && apt-get install -y sudo
echo "nobody ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/nobody
# Execute commands as the nobody user
su - nobody -s /bin/bash -c '
echo "Current user: $(whoami)"
echo "Current UID: $(id -u)"
echo "Attempting sudo whoami..."
sudo whoami
echo "sudo exit status: $?"
'
securityContext:
allowPrivilegeEscalation: true # Explicitly allowing escalationWhen you run this pod, you'll see:
bash
kubectl apply -f privilege-escalation.yaml
pod/privilege-escalation created
kubectl get pod
NAME READY STATUS RESTARTS AGE
privilege-escalation 1/1 Running 0 5s
kubectl logs privilege-escalation
Current user: nobody
Current UID: 65534
Attempting sudo whoami...
rootThe nobody user successfully escalated to root using sudo.
Now let's see what happens when we set allowPriviliegeEscalation: false
pod.yaml
securityContext:
allowPrivilegeEscalation: falseLet's get the logs of the privilege-escalation-false pod:
bash
kubectl get pod
NAME READY STATUS RESTARTS AGE
privilege-escalation-false 1/1 Running 0 3s
kubectl logs privilege-escalation-false
Current user: nobody
Current UID: 65534
Attempting sudo whoami...
sudo: The "no new privileges" flag is set, which prevents sudo from running as root.
sudo: If sudo is running in a container, you may need to adjust the container configuration to disable the flag.
sudo exit status: 1The kernel blocks the privilege escalation attempt.
Even though sudo is installed and configured, the no_new_privs flag prevents the process from gaining root privileges.
This setting works hand-in-hand with runAsNonRoot and Linux capabilities.
Even if a container includes a binary that would normally let it elevate to root, this flag ensures it won't be allowed to do so.
It's especially useful for securing containers that use third-party tools or packages, where you might not know exactly what's inside.
For example, an image based on a general-purpose Linux distribution might contain sudo or su commands that could otherwise be misused.
In most production environments, it's safe—and recommended—to set allowPrivilegeEscalation to false for every container unless you have a clear, documented reason not to.
pod.yaml
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
add: ["CHOWN"]This container runs as a non-root user, cannot elevate privileges, and only has one additional capability.
Just enough to perform a required task.
With privilege escalation locked down, the next layer of defense is the container's filesystem.
Even if an attacker gains access, they shouldn't be able to modify the container's binaries, drop malware, or tamper with startup logic.
But first, it's important to understand the worst-case scenario: containers that bypass all isolation.
Privileged Containers
Privileged containers override or nullify many kernel-level security mechanisms like seccomp, AppArmor, SELinux.
Setting privileged: true field in the securityContext field for the container, removes nearly all security boundaries between the container and the host.
pod.yaml
spec:
containers:
securityContext:
privileged: true # Never do this unless absolutely necessaryA privileged container has access to all host devices, can see all processes on the host, and bypasses most security restrictions.
It's equivalent to running with all Linux capabilities and more.
Under the hood, privileged mode disables multiple layers of isolation:
- It grants access to the host PID namespace, so the container can see and interact with all system processes.
- It shares the host's network and device namespaces, bypassing network isolation and exposing physical interfaces and hardware devices.
- It allows mount operations, including remounting sensitive filesystems like
/proc,/sys, or even the host root.
For cgroups, the process still runs within resource limits, but privileged containers can often manipulate cgroup settings themselves, potentially escaping restrictions or affecting other containers.
The result is that privileged containers behave more like virtual machines than isolated processes.
This is why they represent such a significant security risk.
In practice, privileged containers should be extremely rare and tightly controlled.
The only legitimate use cases are typically system-level tools like: Container runtime components (like containerd), Network plugins that need to configure host networking, Storage drivers that manage host volumes.
If you believe your workload needs privileged: true, first validate whether granting a specific capability solves the problem.
If that doesn't work, document exactly why privileged access is required and implement compensating controls like network policies and admission controllers.
readOnlyRootFilesystem
Most containers don't need to write to their own filesystem after startup.
In fact, allowing them to do so introduces unnecessary risk.
If an attacker compromises the container, a writable root filesystem makes it easier to drop malicious binaries, overwrite scripts, or tamper with logs and config files.
Kubernetes allows you to lock this down using the readOnlyRootFilesystem option.
Under the hood, this setting passes a read-only flag to the container runtime when the root filesystem mount is created.
The container runtime then ensures that the root of the container is mounted with readOnly: true.
Any write attempts to paths like /bin, /etc, or /var will fail unless a writable volume is mounted to override that location.
It's enforced entirely by the Linux kernel, so even if an attacker gains access, they can't persist changes to the image.
pod.yaml
spec:
containers:
securityContext:
readOnlyRootFilesystem: trueWhen readOnlyRootFilesystem is enabled, the container runtime mounts the container's root filesystem in read-only mode.
This is done at container startup, before any processes are launched, using the container's dedicated mount namespace.
That namespace provides an isolated view of the filesystem, and within it, the runtime uses the standard Linux mount() syscall with the MS_RDONLY flag.
This flag tells the kernel to treat the mount as read-only, just as if you had run mount -o ro on a physical system.
The Virtual File System (VFS) is the kernel subsystem that handles all file operations.
Internally, the kernel marks this mount with the MNT_RDONLY flag, which becomes visible and enforceable at the VFS layer.
When a process inside the container attempts a write operation, such as write(), mkdir(), or unlink(), the syscall passes through the VFS.
At this point, the VFS checks the mount flags.
If it sees MNT_RDONLY set, the kernel immediately rejects the request.
Even if an attacker has shell access or tries to execute payloads from within the container, they won't be able to write to any path unless a writable volume has been mounted over it.
They can't drop binaries, modify config files, or make any lasting changes to the image.
The root filesystem remains immutable for the lifetime of the container.
Not all applications are compatible with a fully read-only root.
Some need to write logs to /tmp, store runtime state in /var/run, or generate temporary files in /home.
In those cases, you can mount writable volumes at those paths to provide the necessary write access.
pod.yaml
volumeMounts:
- name: tmp
mountPath: /tmp
volumes:
- name: tmp
emptyDir: {}This configuration creates an isolated in-memory volume and gives the container a safe place to write while keeping the rest of the filesystem immutable.
We've now locked down who the container runs as, what it's allowed to do, and where it can write.
But that's only part of the picture.
Containers frequently interact with mounted volumes and those volumes bring their own permission and access challenges.
Capabilities limit what a process can do, but they don't restrict which system calls a process can actually make.
That's where Seccomp comes in.
Seccomp Profiles
Seccomp (short for secure computing mode) provides syscall-level control by attaching a BPF (Berkeley Packet Filter) program directly to a process.
Each time the process invokes a system call, the kernel intercepts it and hands the syscall number and arguments to the BPF filter.
This happens in kernel mode, just before the syscall is executed.
The filter can then allow the call, block it with an EPERM, terminate the process with a SIGSYS, or log the attempt for auditing.
Unlike capabilities, which act at a higher abstraction level, Seccomp operates on the syscall interface.
It lets you specify which syscalls a process is allowed to use and deny everything else by default.
 1/4
1/4JVM applications make system calls through the kernel to access system resources like the network.
 2/4
2/4The kernel uses capabilities to control privileged operations, checking permissions for specific syscalls like CHOWN and CAP_NET_ADMIN.
 3/4
3/4Seccomp adds another security layer that can block specific syscalls like ioctl while allowing others through BPF filtering.
 4/4
4/4Multiple syscalls can be filtered simultaneously, with seccomp allowing setsockopt while blocking ioctl, providing fine-grained syscall control.
In container runtimes, the default Seccomp profile explicitly allows just over 300 common syscalls required for typical container workloads.
Everything else is blocked using SCMP_ACT_ERRNO, which causes the syscall to fail with a permission error.
Blocked syscalls include:
mount/umount– filesystem mountingptrace– process tracing and debuggingreboot– system rebootsetns– namespace manipulationkeyctl– kernel keyring access
By default, Kubernetes applies no seccomp profile.
The RuntimeDefault seccomp profile allows only a minimal set of system calls required for basic container execution.
To apply the RuntimeDefault seccomp profile, the kubelet must be started with the --seccomp-default flag.
This enables RuntimeDefault as the default profile for all pods that do not explicitly specify one.
pod.yaml
spec:
securityContext:
seccompProfile:
type: RuntimeDefaultWhen the kubelet starts a container with this setting, it passes the seccomp configuration to the container runtime via CRI.
The runtime loads its built-in BPF filter program and attaches this filter to the container process using the seccomp() syscall.
From that point on, every syscall from the container is evaluated by the BPF program.
If you need more granular control, you can define a custom seccomp profile.
To achieve this, you need to create a JSON file on the node and reference it in the pod spec.
app-specific.json
{
"defaultAction": "SCMP_ACT_ERRNO",
"architectures": ["SCMP_ARCH_X86_64"],
"syscalls": [
{
"names": ["read", "write", "open", "close", "stat", "fstat"],
"action": "SCMP_ACT_ALLOW"
},
{
"names": ["socket", "connect", "accept"],
"action": "SCMP_ACT_ALLOW",
"args": [
{
"index": 0,
"value": 2,
"op": "SCMP_CMP_EQ"
}
]
}
]
}This seccomp profile blocks all system calls by default using SCMP_ACT_ERRNO and explicitly allows basic file operations.
It also permits socket-related calls only when the first argument (domain) is 2 (AF_INET, i.e., IPv4).
To reference it in your pod.
pod.yaml
securityContext:
seccompProfile:
type: Localhost
localhostProfile: profiles/app-specific.jsonThe most restrictive pod security configuration blocks all Linux capabilities and restricts syscalls to a minimal safe set:
pod.yaml
securityContext:
seccompProfile:
type: RuntimeDefault
allowPrivilegeEscalation: false
runAsNonRoot: true
capabilities:
drop: ["ALL"]If your application fails, the process usually receives an EPERM (Operation not permitted) error.
You can use strace to trace syscall activity inside the container:
bash
kubectl debug -it your-pod --image=nicolaka/netshoot -- strace -f -e trace=all your-commandIf audit logging is enabled, you can query the system audit logs for seccomp violations:
bash
ausearch -m SECCOMPStart with the RuntimeDefault profile and only create custom profiles if you have specific security requirements or compliance needs.
After confirming your application runs safely under baseline constraints, incrementally tighten syscall restrictions with a custom seccomp profile.
Many applications work fine with the default restrictions, but some (especially those doing system-level operations) may need careful tuning.
AppArmor
AppArmor provides another layer of access control by restricting programs to a limited set of resources through path-based access control profiles.
Unlike seccomp which filters system calls, AppArmor focuses on file system access, network access, and capability usage.
For example, a container might use seccomp to block mount() syscalls completely, while AppArmor ensures that even if file operations are allowed, they can only access specific directories.
Kubernetes supports AppArmor through annotations, but it requires profiles to be loaded on each node beforehand.
Most production environments rely on the combination of capabilities, seccomp, and Security Context settings rather than adding AppArmor complexity.
You might wonder why we need both.
They operate at different levels.
AppArmor profiles can be applied at either the pod level or the container level.
When both are specified, the container-level profile takes precedence over the pod-level one.
pod.yaml
spec:
securityContext:
appArmorProfile:
type: RuntimeDefaultThis setting tells the container runtime to apply its default AppArmor profile to the container.
That profile defines what files, paths, and kernel resources the process can access, using a declarative rule set enforced by the kernel.
While AppArmor controls where and what a process can touch, Linux capabilities define whether the process is allowed to perform certain privileged operations.
AppArmor builds on capabilities by further restricting how those operations interact with the filesystem and system objects.
It doesn't grant privilege—it scopes it to safe, expected paths.
For example, AppArmor may be used to allow a program to have read access to /etc/passwd, but not /etc/shadow.
Seccomp adds a third layer by filtering which system calls the process can execute, and under what conditions.
 1/3
1/3JVM applications with CAP_NET_ADMIN can configure network interfaces, routing tables, and iptables rules through system calls to the kernel.
 2/3
2/3AppArmor adds a second security layer that restricts syscalls to only work on virtual devices, for example.
 3/3
3/3Seccomp provides the final layer by filtering specific syscalls like
ioctlandsetsockopt.
So while capabilities check what kind of privilege a process has, and AppArmor checks where it can apply it, seccomp governs the syscall-level behavior.
fsGroup and supplementalGroups
Even with the container process running as a non-root user, file access can still become a problem, especially when working with mounted volumes.
Many Kubernetes volumes, such as those backed by NFS, Ceph, or even emptyDir, are shared between containers or pods.
These volumes often come with default ownership settings that don't match the user your container is running as.
The result? Permission denied errors occur when your application tries to read or write files.
To fix this, Kubernetes provides fsGroup.
When fsGroup is set, the kubelet takes care of applying it during volume mount.
It recursively changes the group ownership (GID) of the mounted volume's files to match the provided fsGroup, using chgrp under the hood.
It also ensures that any new files created by the container will inherit that group ID, making them accessible to the process even if it runs as a non-root user.
This only affects mounted volumes - not the image's internal filesystem - and doesn't require changes inside the container image itself.
pod.yaml
spec:
securityContext:
fsGroup: 2000It also ensures that any files created within those volumes are owned by that group, allowing non-root processes to access them as long as they're part of the same group.
Let's say your container runs as UID 1000, and you set fsGroup: 2000, here's what happens next.
When a Pod with fsGroup is scheduled to a node, the kubelet's volume manager prepares the volume mount points.
Before the container runtime starts the container, the kubelet executes volume setup operations on the host.
The kubelet mounts the volume from its source (e.g., NFS, hostPath, etc.) to a staging path on the host.
The kubelet then applies the ownership and permission changes based on fsGroup using host-level system calls.
It uses the equivalent of chown -R :2000 on the mounted volume.
If fsGroupChangePolicy is set to OnRootMismatch, it only changes ownership if the root directory's group doesn't match the fsGroup.
Only after the ownership changes are complete does the kubelet instruct the container runtime to start the container with the volume mounted.
 1/4
1/4Kubelet receives a pod with fsGroup 2000 and instructs the container runtime to start the container with the volume mounted.
 2/4
2/4The kubelet mounts the volume to a staging path and applies the fsGroup ownership using
chown -R :2000. 3/4
3/4The container starts as UID 1000 while the volume ownership changes are applied by the kubelet on the host.
 4/4
4/4The container can now read and write to the volume since it's part of group 2000, which owns the mounted files.
This is especially useful for logging directories that need to be shared across containers, database volumes that expect specific permissions, web servers that serve files from a mounted volume.
If your application needs access to multiple groups, Kubernetes also supports supplementalGroups.
pod.yaml
securityContext:
supplementalGroups: [2000, 3000]This adds additional GIDs to the process's group list.
It's worth noting that both fsGroup and supplementalGroups affect volumes only.
They do not change permissions inside the container image itself—only the volumes mounted at runtime.
With this, you can safely manage shared file access without resorting to running as root or globally relaxing file permissions.
How fsGroup Works with CSI Volumes
The Container Storage Interface (CSI) transforms how Kubernetes handles volume permissions compared to traditional in-tree volumes.
This affects how fsGroup settings get applied to mounted storage.
When a pod with a CSI volume specifies an fsGroup, the kubelet communicates with the CSI driver through a Unix socket.
Unlike with in-tree volumes where the kubelet handles everything, CSI drivers take over significant responsibilities.
The driver mounts storage to a staging path first, then to the final target path where containers access it.
Whether the fsGroup gets applied depends on the driver's declared capabilities.
Since Kubernetes v1.19, CSI drivers explicitly report their fsGroup support through the CSI_VOLUME_FSGROUP_POLICY capability.
CSI drivers implement one of three distinct policies:
- With the
Nonepolicy, the driver doesn't support permission modifications at all. The kubelet won't attempt any ownership changes, leaving permissions as-is on the volume. - Under the
Filepolicy, the kubelet behaves similarly to in-tree volumes, recursively changing ownership and permissions on all files and directories to match the specified fsGroup. - The
ReadWriteOnceWithFSTypepolicy represents a middle ground. The kubelet only applies fsGroup changes when the volume has a specified filesystem type and uses the ReadWriteOnce access mode.
This flexible approach solves several real-world problems:
- Recursive permission changes on large volumes can severely impact performance and delay pod startup.
- Many distributed storage systems implement permissions differently than Linux's user/group model.
- Enterprise storage platforms often have specialized security requirements that would conflict with blanket permission changes.
Live Debugging: Diagnosing SecurityContext Failures
Security settings make more sense when they're tied to actual use cases.
Let's look at a few possible scenarios where Kubernetes Security Contexts helped solve concrete problems without compromising functionality.
The first example is a Legacy Monitoring Tool.
A team could be migrating an older monitoring agent into Kubernetes.
The agent needs low-level access to inspect processes and collect network metrics.
Initially, the container ran as root to make this work, but this created security concerns during audits.
Instead of keeping full root access, the team should drop all capabilities and add only what is needed.
pod.yaml
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
add: ["SYS_PTRACE", "NET_ADMIN"]The container worked exactly as before, but with a dramatically reduced risk profile.
Second example is a backup process that needs chown.
A database backup job is failing in Kubernetes because file ownership needs to be changed on a mounted volume.
Running the container as root fixed it, but isn't acceptable from a compliance perspective.
Instead, you can keep the container running as a non-root user and add the CHOWN capability.
pod.yaml
securityContext:
runAsUser: 1001
runAsNonRoot: true
capabilities:
drop: ["ALL"]
add: ["CHOWN"]Combined with fsGroup, the container could manage file ownership correctly without elevated privileges.
Third use case is Read-Only containers for public-facing apps.
A frontend application serving static files is containerized and exposed to the internet.
As a precaution, the container running the application is configured to run with a read-only root filesystem.
pod.yaml
securityContext:
runAsUser: 1000
readOnlyRootFilesystem: trueAn emptyDir volume is used and mounted to /tmp to handle temporary files.
This setting protects the container from unauthorized file modifications in case of compromise, while keeping the application fully functional.
A key implementation detail here is volume setup and ownership adjustments are handled by the kubelet on the host, not inside the container.
The kubelet runs as root and has the necessary privileges to create volumes, mount them into the container's namespace, and adjust file ownership to match the container's runAsUser and runAsGroup.
The container itself doesn't need any elevated privileges to access these volumes.
The ownership changes are ephemeral—they persist only for the lifetime of the Pod's volumes and are scoped to the container's view of the filesystem.
Now, let's walk through a real troubleshooting scenario where a container security context silently breaks your workload.
Troubleshooting: When Security Context Conflicts with Container Behavior
You deploy a Node.js application that needs to write logs, but the pod keeps crashing with permission errors.
nodejs-app.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodejs-app
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: true
fsGroup: 2000
containers:
- name: app
image: node:18
command: ["node"]
args:
- -e
- |
const fs = require('fs');
const path = '/var/log/app.log';
fs.writeFileSync(path, 'Starting app');
console.log('App started');Deploy this pod and check the status:
bash
kubectl apply -f nodejs-app.yaml
pod/nodejs-app created
kubectl get pod nodejs-app
NAME READY STATUS RESTARTS AGE
nodejs-app 0/1 Completed 2 (21s ago) 91s
kubectl logs nodejs-app
Error: EACCES: permission denied, open '/var/log/app.log'
at Object.openSync (node:fs:596:3)
at Object.writeFileSync (node:fs:2322:35)
at [eval]:1:30
at runScriptInThisContext (node:internal/vm:143:10)
at node:internal/process/execution:100:14
at [eval]-wrapper:6:24
at runScript (node:internal/process/execution:83:62)
at evalScript (node:internal/process/execution:114:10)
at node:internal/main/eval_string:30:3 {
errno: -13,
syscall: 'open',
code: 'EACCES',
path: '/var/log/app.log'
}
Node.js v18.20.8Let's investigate what's happening inside the container:
nodejs-debug.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodejs-debug
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: true
fsGroup: 2000
containers:
- name: debug
image: node:18
command: ["sh", "-c"]
args:
- |
echo "Current user: $(whoami)"
echo "User ID: $(id -u)"
echo "Group ID: $(id -g)"
echo "Groups: $(id -G)"
ls -la /var/log/
touch /var/log/test.log 2>&1 || echo "Cannot write to /var/log"
sleep 3600The output reveals:
bash
kubectl logs nodejs-debug
Current user: node
User ID: 1000
Group ID: 1000
Groups: 1000 2000
drwxr-xr-x 1 root root 4096 May 30 10:00 /var/log/
Cannot write to /var/logThe /var/log directory is owned by root and not writable by our user!
First solution is using a writable volume.
Let's add an emptyDir volume for logs:
nodejs-fixed-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodejs-fixed-volume
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: true
fsGroup: 2000
volumes:
- name: logs
emptyDir: {}
containers:
- name: app
image: node:18
volumeMounts:
mountPath: /var/log
command: ["sh", "-c"]
args:
- |
echo "Volume permissions:"
ls -la /var/log
node -e "
const fs = require('fs');
fs.writeFileSync('/var/log/app.log', 'App started successfully!');
console.log('Success! Log written');
"
echo "Log contents:"
cat /var/log/app.logLet's apply the file:
bash
kubectl apply -f nodejs-fixed-volume.yaml
pod/nodejs-fixed-volume createdStream the logs:
bash
kubectl logs nodejs-fixed-volume
Volume permissions: total 12
drwxrwsrwx 2 root 2000 4096 Jul 4 07:44 .
drwxr-xr-x 1 root root 4096 May 20 00:00 ..
-rw-r--r-- 1 node 2000 25 Jul 4 07:45 app.log
Success! Log written
App started successfully!This works!
The fsGroup ensures the volume is writable by our container.
Let's consider an alternative approach: adjusting the application's log path.
Sometimes it's easier to change where the app writes:
nodejs-home.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodejs-home
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: true
containers:
- name: app
image: node:18
command: ["sh", "-c"]
args:
- |
echo "Home directory: $HOME"
echo "Home permissions:"
ls -la "$HOME"
node -e "
const fs = require('fs');
const path = process.env.HOME + '/app.log';
fs.writeFileSync(path, 'Using home directory');
console.log('Success using home dir');
"This works too!
But for production, that's not enough.
A production-ready solution combines all security best practices into a single configuration:
nodejs-production.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodejs-production
spec:
securityContext:
runAsUser: 1000
runAsNonRoot: true
fsGroup: 2000
fsGroupChangePolicy: "OnRootMismatch"
volumes:
- name: app-logs
emptyDir: {}
- name: tmp
emptyDir: {}
containers:
- name: app
image: node:18
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop: ["ALL"]
volumeMounts:
- name: app-logs
mountPath: /logs
- name: tmp
mountPath: /tmp
env:
- name: NODE_ENV
value: "production"
command: ["node"]
args:
- -e
- |
const fs = require('fs');
const logFile = '/logs/app.log';
// Verify we can write
fs.writeFileSync(logFile, `App started at ${new Date().toISOString()}\n`);
console.log('Application running securely!');
// Simulate app work
setInterval(() => {
fs.appendFileSync(logFile, `Heartbeat at ${new Date().toISOString()}\n`);
}, 5000);This version respects all security best practices, and ensures /logs and /tmp are writable while the root filesystem remains read-only.
So, what did we learn from these excercises?
Many containerized applications attempt writes to system paths like /var/log or /run due to defaults inherited from upstream Linux software.
With non-root users and a read-only root, those paths break.
fsGroup fixes that by making volumes writable to your container's user.
Security needs layers—runAsNonRoot, readOnlyRootFilesystem, and dropped capabilities each block different risks.
Don't apply everything at once.
Add one control, test, then move to the next.
When things fail, use a debug shell.
Check id, ls, and try writing files to see what's blocked.
Summary and Best Practices
Securing containers in Kubernetes isn't about one magic setting, it's about layering protections that make it harder for things to go wrong.
Treat Security Contexts as part of your architecture.
Here's how to achieve this effectively.
Start by avoiding root entirely.
Always set runAsNonRoot: true and define an explicit runAsUser.
Even though root inside a container isn't host root, it still carries unnecessary privilege.
Next, drop all Linux capabilities by default.
Most applications don't need them.
Use drop: ["ALL"] as your baseline, and add back only what's strictly required—like NET_ADMIN for low-level networking.
Block privilege escalation.
Set allowPrivilegeEscalation: false to prevent processes from gaining extra rights via setuid binaries or other mechanisms.
Then lock down the root filesystem.
If the app doesn't need to write to its own image, use readOnlyRootFilesystem: true.
This stops attackers from modifying binaries or installing tools.
Mount temporary writable volumes (like emptyDir) only where necessary.
To make them accessible to non-root users, set fsGroup to match the container's runtime group ID.
Finally, don't trust third-party images by default.
Many assume root or lack minimal security settings.
Review base images carefully, override insecure defaults, and scan for embedded risks.
Each of these controls blocks a specific class of attacks—privilege escalation, lateral movement, and persistence.
Build incrementally, test behavior, and validate permissions at runtime.